Vertical Federated Learning for Credit Scoring Models Without Label Leakage
Industry
Banking sector, financial services, scoring products
Technology
Vertical Federated Learning (VFL)
Data type
Tabular (structured) data
ML models
Gradient Boosting (GBDT)
ML task
Credit scoring
Product
Guardora VFL

The customer is a vendor company in the field of analytical products and predictive analytics that provides credit-scoring services to commercial banks.
The vendor holds an extensive body of data about users and, on this basis, builds creditworthiness assessment models for financial institutions.
The vendor’s clients use these models to make credit decisions, manage risk, and counter fraud.
High requirements for compliance with personal-data protection legislation
Need to enrich models with external data sources without compromising confidentiality
Use of predictive analytics for credit scoring and risk assessment
The analytics-product vendor provides credit-scoring services to commercial banks. In the current process, the joint model is built using an ensembling method (stacking): each party trains its own model on its own data, after which the outputs of both models are combined into a final score.
To train the model on the vendor’s side, the labels (the target variable) must be transferred from the bank in the clear. The labels are confidential bank information containing the historical creditworthiness data of its clients. Transferring the labels requires agreement between the parties and compliance with internal information-security and compliance procedures.
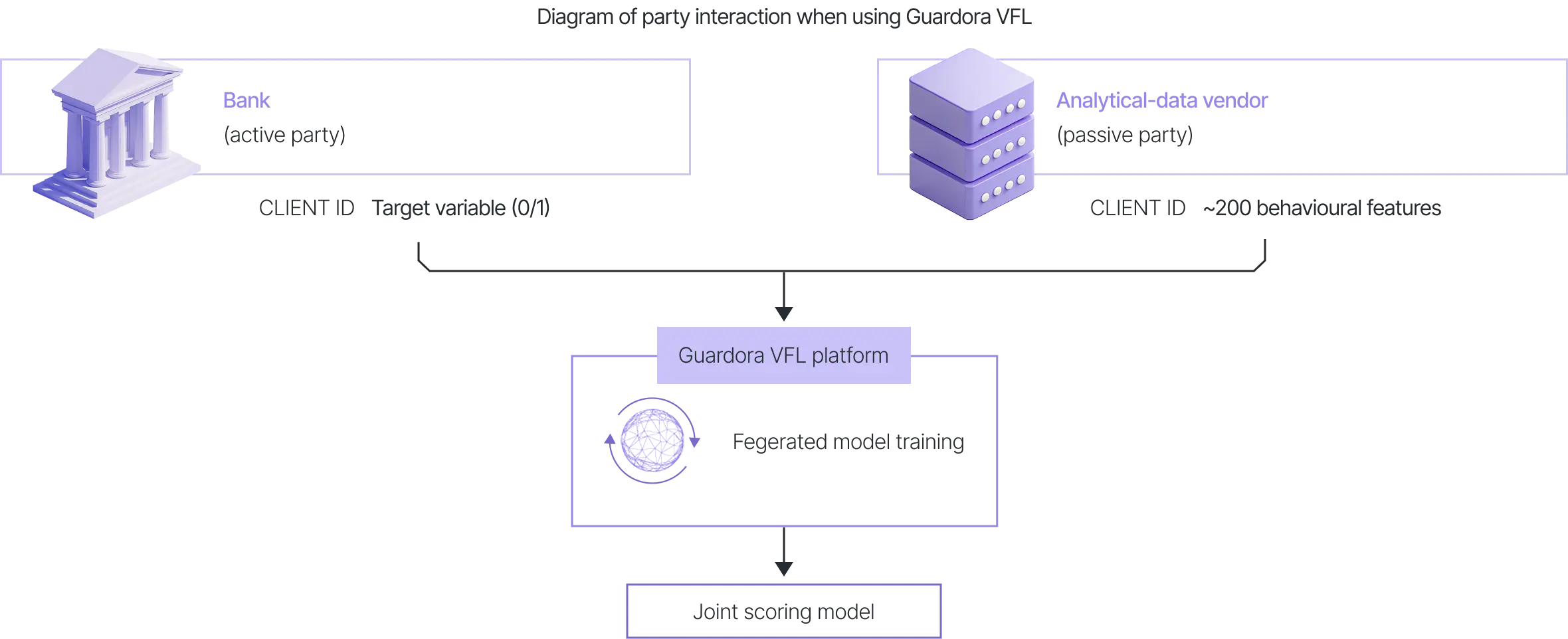
The vendor’s core question: can different companies build a single ML model without disclosing data to each other, so that the final model uses the datasets of all parties, and the model quality is better than the quality of the individual local models?
Testing objective: to compare the quality of a model trained using Vertical Federated Learning (VFL) with the quality of each party’s local model, and with the quality of the two-model ensemble (stacking), on the condition that within VFL, the labels are not transferred between parties.
Active party (bank): holds the labels (the target variable, a binary creditworthiness indicator 0/1), the client identifiers, and some of the features.
Passive party (vendor): holds ~200 features for the same clients, but has no labels.
The testing was performed using a Gradient Boosting on Decision Trees (GBDT) model (a model consisting of 100 trees with a maximum depth of 6), the primary model for working with tabular data.
Data protection is provided under two security modes:
The table below presents the test results:
| Approach | ROC_AUC | Label transfer |
|---|---|---|
| Local model of party A | 67.6 | Not required |
| Local model of party B | 70.1 | Required |
| Ensemble of two models (stacking) | 71.3 | Required |
| Guardora VFL (GBDT) | ≈ 81.3 | Not required |
For the computation of party B’s local model within the test scenario, the labels were used.
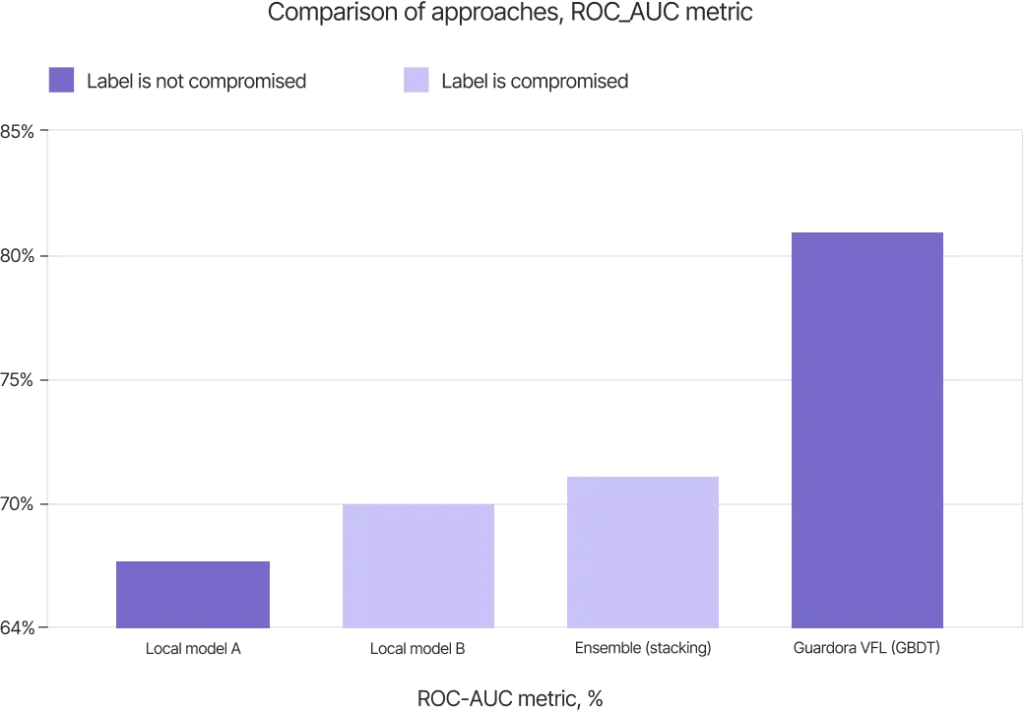
Key result: following hyperparameter optimization, the VFL model achieved performance exceeding that of a two-model ensemble (stacking) and significantly outperforming each party’s local models. No label sharing occurred between participants.
Thus, in the modelled scenario, the vendor’s clients (banks) obtain a model that surpasses ensemble-level performance without label sharing.
The training and inference speed of the federated model is comparable to the training and inference speed of a standard scoring model:
The table below shows the ROC_AUC results of the federatively trained model for different numbers of data rows (samples) and the applied training method, gradient boosting.
| No | Sample | Encryption | ROC AUC | Time |
|---|---|---|---|---|
| 1 | 10K | - | 76.72 | 36.5 s |
| 2 | 50K | - | 79.15 | 1.5 m |
| 3 | 100K | - | 79.06 | 2.9 m |
| 4 | 200K | - | 79.77 | 5.9 m |
| 5 | 300K | - | 78.82 | 8.9 m |
| 6 | 10K | + | 76.32 | 38 m |
| 7 | 50K | + | 78.78 | 1.4 h |
| 8 | 400K | + | 81.30 | 13h |
*The results were achieved through experiments involving changes to the model hyperparameters
In the described credit-scoring use case on tabular data with GBDT (100 trees, max depth 6), Guardora VFL achieved ROC AUC ≈ 81.3, outperforming a stacking ensemble of two separately trained models (71.3), the bank's local model (70.1) and the vendor's local model (67.6). Also the stacking ensemble requires label transfer between parties, while Guardora VFL does not.
Federated learning uses the data of both parties to build a unified model without violating confidentiality requirements.
The training speed without encryption is considered high, and with encryption, acceptable for industrial use.
The solution has undergone full-scale testing within the perimeter of a major technology company on real-world data.
