Federated Machine Learning for Scoring in BFSI
Industry Domains:
Banking, Financial Services, Insurance
Technique:
Vertical Federated Learning (VFL)
Data type:
Tabular (structured) data
ML-model:
Decision Trees (XGBoost)
ML-tasks:
Credit scoring and fraud detection
Challenges:

A portrait of Federated Learning users includes representatives from the banking and insurance sectors, who use models for risk prediction, borrower assessment, and fraud prevention.
High demand for compliance with data protection legislation
Need for integration of diverse data sources
Use of data for predictive analytics and credit assessments
The main challenge is training scoring models using confidential data from various sources, such as banks and insurance companies, without disclosing the data itself. The tasks include protecting data from leaks, ensuring anonymity, and complying with privacy laws.
Federated Machine Learning is used to build credit scoring and risk assessment models without revealing personal data.
The issues include:

The data does not leave the owner's perimeter. The ML specialist and resources are within the data owner's perimeter
Secured synchronization of local and global model parameters with the server
Final model quality assessment
Model application within the data owner's perimeter and interpretation of the obtained results
To enable the extraction of knowledge from the data of both participants, a vertical federated learning infrastructure was required.
The nature of the original data determined the choice of target model as gradient boosting based on decision trees using the XGBoost implementation.
The side with the target class labels is referred to as the Server Side, while the side without targets is called the Client Side.
For the public demonstration of results, a dataset was used that includes:
Banking data is on the Server Side, totaling 78,806 records, each containing 12 feature descriptions of a person. Auto insurance data is on the Client Side, with 97,224 records and 9 features for each person.
Each dataset contains an ID field, enabling the matching of data related to the same individual. Each person from the intersection of datasets is described by 21 features, split between the two sides.
Part of the intersecting data was set aside as a test set of 25,668 records, with the rest used for training.
Two training cycles of an XGBoost model were conducted:
For both cases, identical model parameters were set:
| 'objective': 'multi:softmax' | 'num_class': 3 |
| 'eval_metric': 'merror' | 'max_depth': 6 |
| learning_rate': 0.1 | 'subsample': 0.8 |
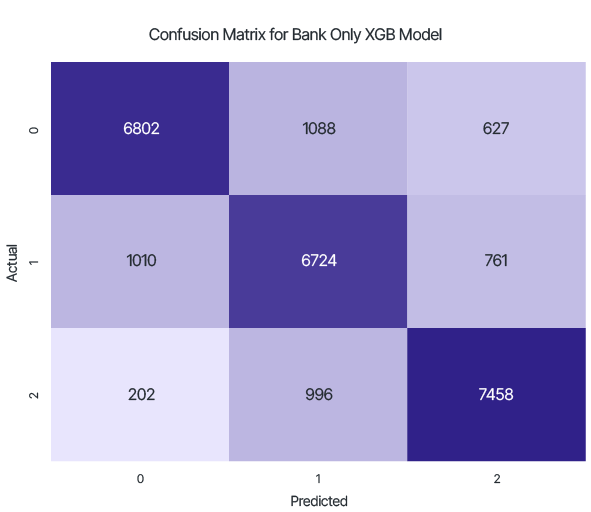
The result of testing the local model trained only on data from the Server Side:
Accuracy: 0.817
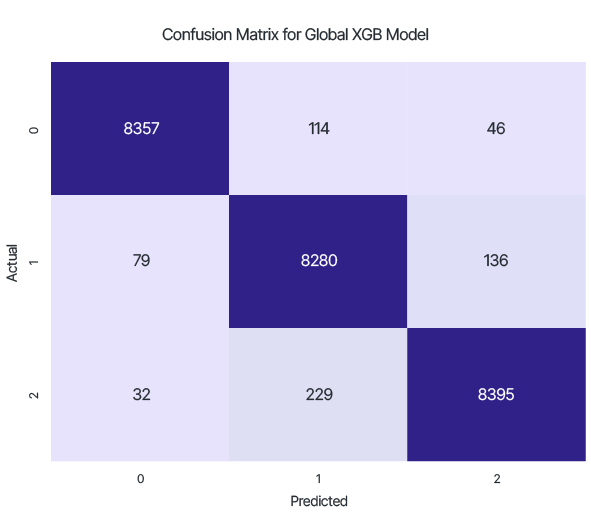
The result of testing the global model, trained on data from both the Server and Client Sides:
Accuracy: 0.975
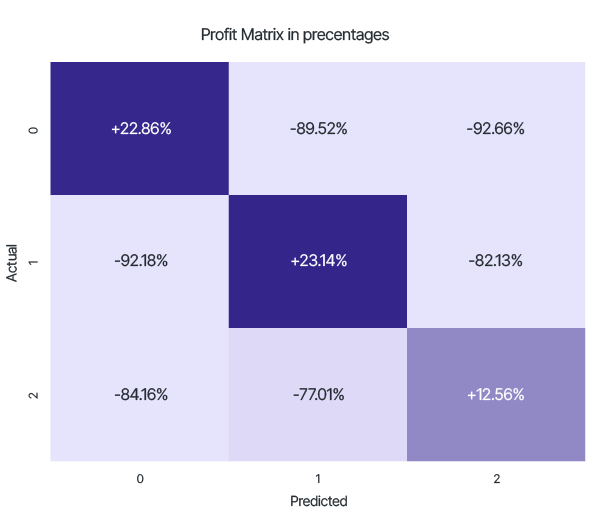
The profit from using this approach compared to the local model's capabilities:
From this matrix, it can be seen that, for example, the number of test samples with a low credit score, but classified by the trained model as high rating, decreased by 92.66% when using the global federated learning model.
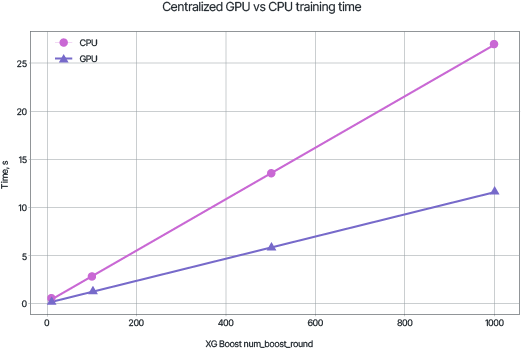
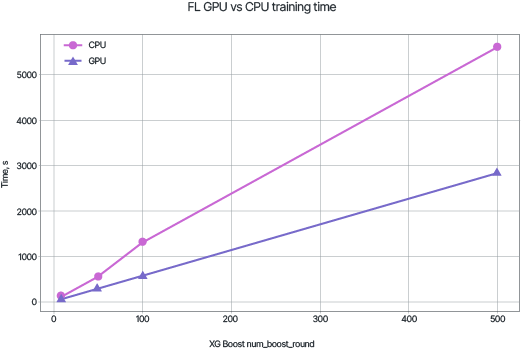
It’s worth noting that the distributed training process takes longer than centralized training. The graphs show the time required to train the model with a specified number of trees using CPU and GPU.
Despite the significant time costs, the high convergence speed of the model allows VFL to remain a practically valuable method for generalizing information from accumulated data.
An increase in the accuracy of credit scoring models by more than 15%
A reduction in the risk of loan defaults and fraud.
An increase in the prediction of customer churn and improvement of customer experience.
A scoring model was trained based on data from multiple sources (bank and insurance) while fully preserving confidentiality.
