Let's first consider the most common case of machine learning today. There is a certain entity that possesses enough data to train a machine learning model.
The model can be arbitrary, ranging from deep neural networks to linear regression.
The interaction of the model with the data generates a solution to a practical problem, such as object detection, audio transcription, and so on.
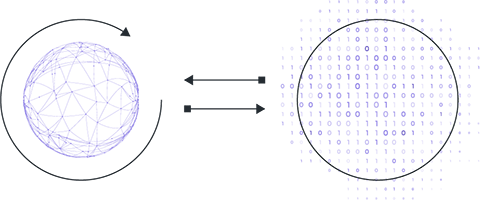
In reality, the data that the model has to work with does not originate from the machine on which the training takes place; they are created elsewhere.

That is, to conduct the analysis, data from various sources must be collected on some central server, e.g., in the cloud.
Federated Learning (FL) is a machine learning paradigm that enables the training of a global model by clients without sharing their local data.
This approach to machine learning not only solves data privacy issues, but also opens new horizons for developing secure and efficient models.


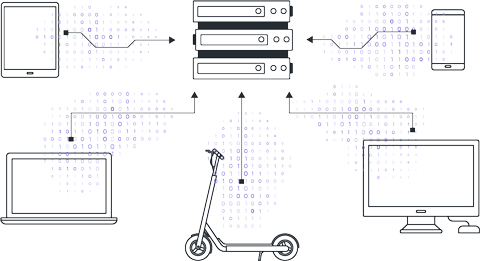
Clients agree on the global model, loss function, and data preprocessing procedures. The central server initializes the global model either randomly or using a pre-trained checkpoint.
The server distributes the parameters of the global model to connected clients. It's important to note that each client starts training using the same model parameters.
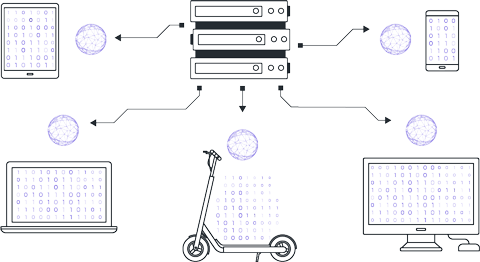
Clients perform local training of model instances on their own data. Local training ranges from a few steps to several epochs depending on initial agreements.

After local training, clients have models with differing parameters due to variations in their local datasets. Clients return these model parameters to the central server.
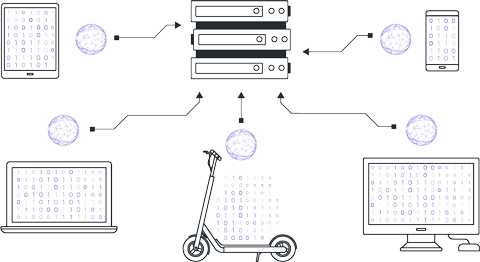
The server receives the model parameters from clients and aggregates them to update the parameters of the global version.
There are various approaches to parameter aggregation, but the most popular method is FedAvg (Federated Averaging), where the received parameters are averaged in a weighted manner according to the sizes of the local datasets.
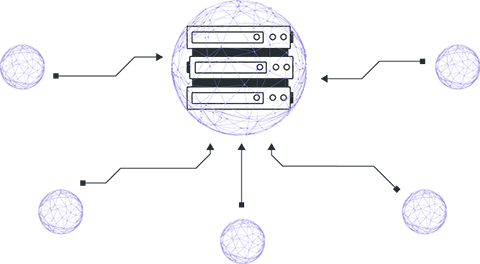
Steps 1-4 constitute one round of the FL, which is repeated until the model converges.
It is important to note that the data itself remains local and only model updates are transmitted to the centralized server and other devices. This approach preserves data privacy by avoiding the need for centralized accumulation.
Like any other technology, the FL, while solving the intended problem, has both positive and negative aspects.
Due to the absence of data transmission, FL minimizes the risk of leaks or unauthorized access to confidential information.
This approach allows for efficient processing of large volumes of data and scaling to a large number of devices without significantly increasing network load or computational resources.
Local copies of models and data distribution among clients help minimize vulnerabilities associated with server failures.
FL enables significant parallelization of the global model training process, eliminating the need for GPU-equipped central servers.
The path from data source to model becomes shorter, reducing the likelihood of data becoming outdated or distorted.
Managing the training process with multiple clients requires a complex system of coordination and agreement, which can complicate system deployment and support.
Differences in client data sets can lead to inconsistencies in models or loss of commonality in the aggregated model.
Computational resources on user devices may be limited, complicating the training of complex models or requiring additional algorithm optimization.
The possibility of attacks on individual devices or servers storing data or model updates necessitates increased attention to cybersecurity and fraud protection.
The difficulty in finding identical data owners willing to solve a similar practical problem.
Nevertheless, FL has found wide application in various fields where sensitive data processing is required, such as medicine (analyzing medical images and patient data), financial services (transaction analysis and fraud detection) and the Internet of Things (processing data from sensors and smart devices).
Thus, FL represents an important technological innovation in the field of PPML (Privacy Preserving Machine Learning), capable of reshaping the landscape of machine learning by making it safer and more accessible across various sectors of the economy.
However, successful implementation requires careful consideration and management of the shortcomings and challenges inherent to this method.