Federated Machine Learning for Fraud Detection in Bank Transactions
Industries
Banks, Payment Systems, FinTech, Fraud Prevention and Detection
Technique
Horizontal Federated Learning (HFL)
Data Types
Tabular
ML Models
Random Forest (RF) and Gradient-Boosted Decision Trees (GBDT)
ML Objectives
Fraud detection in bank card transactions
PPML tasks

The bank is interested in preventing card fraud to protect customer funds, minimize its own financial losses and increase customer trust.
The payment system aims to ensure the security of transactions, reduce reputational risks associated with fraudulent transactions, and maintain user confidence in its services and the banking system as a whole.
Protecting the confidentiality of customer data is a critical task for both the bank and the payment system, especially in the context of stricter regulation of personal data processing.
Striving to reduce financial losses and minimize risks through the implementation of effective fraud prevention technologies.
Strengthening customer confidence by enhancing the safety and reliability of financial transactions.
Business challenge: detecting fraudulent activities involving bank cards in the transaction process.
The main objective is to improve the accuracy of real-time fraud detection while protecting personal data.
Technical challenge: designing and implementing a federatively trained ML model for fraudulent transaction detection based on joint bank and payment system data.
The model should:
Random Forest and Gradient-Boosted Decision Trees (GBDT) are considered as machine learning models that provide high accuracy and reliability in fraud detection tasks.

The data does not leave the owner profile. The ML specialist and resources are inside the data owner framework
Secure synchronization of local and global model parameters with the server
Quality check of the final model
Application of the model within the data owner framework and interpretation of the results obtained
As part of a collaboration between banks and payment systems, Guardora demonstrated the practical value of federated machine learning (FL) technology in detecting fraud in bank transactions.
FL participants have different pipelines for generating feature spaces. For the features that form the intersection of these spaces, retrieval and preprocessing schemes have been harmonized.
In order to provide open peer auditing, the FL process was deployed in a private cloud with two client servers and one aggregation server.
The specificity of the fraudulent transaction detection task lies in the enormous class imbalance. About 0.01-0.001 transactions represent frauds in the real data stream. This prevents the widespread adoption of ML algorithms to solve such a problem.
Small financial organizations that do not have a sufficiently representative dataset are particularly susceptible to fraud. Often, transaction classification is done by building complex rule sets ("rule based").
Participants reported that datasets included groups of transaction characteristics such as payer data, time and financial data, payment information, geographic information, network information, device information, profiled behavior, and others.
Description of datasets
| data_A | data_B | |
|---|---|---|
| Number of attributes | 93 | 93 |
| Number of legal | 69341 | 29141 |
| Number of frauds | 843 | 859 |
| Percentage of frauds | 0.012 | 0.029 |
A characteristic class disparity can be seen. Participants decided to use decision tree-based models, thus the performance of Random Forest (RF) and Gradient-Boosted Decision Trees (GBDT) models was compared.
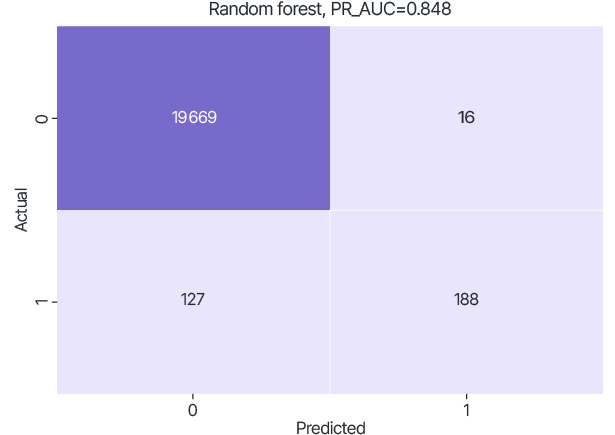
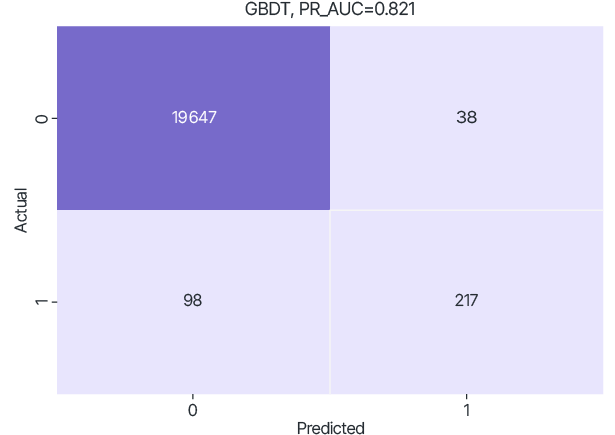
The dataset on which the trained model was tested was generated and fixed by randomly selecting 20% of each set. Due to the significant imbalance, the PR-AUC metric was used, which calculates the area under the curve that represents the Precision to Recall ratio at different classification thresholds. Confusion matrix was used to visualize the classification ability of the trained model at threshold 0.5.
Test results of RF models trained only on local datasets.
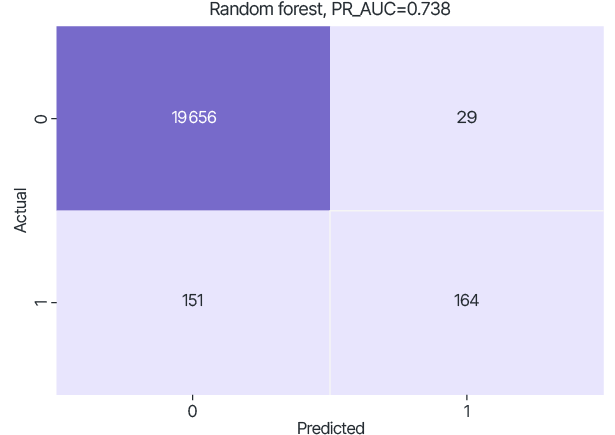
data_A
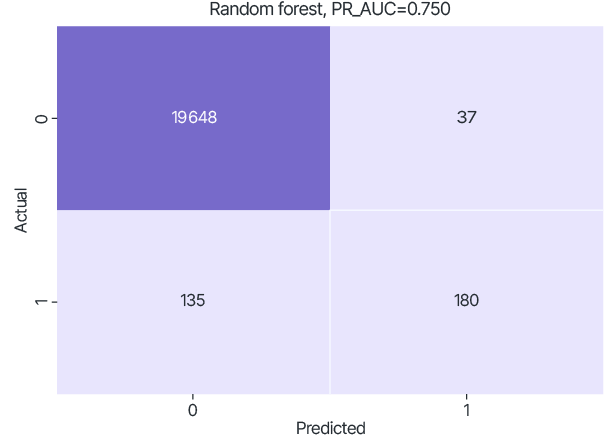
data_B
Guardora has developed a federated version of the RF and GBDT models.
RF and GBDT models were federatively trained with the same hyperparameters as in the local training cases.
Thus, according to the PR-AUC metric, the RF model performed better.
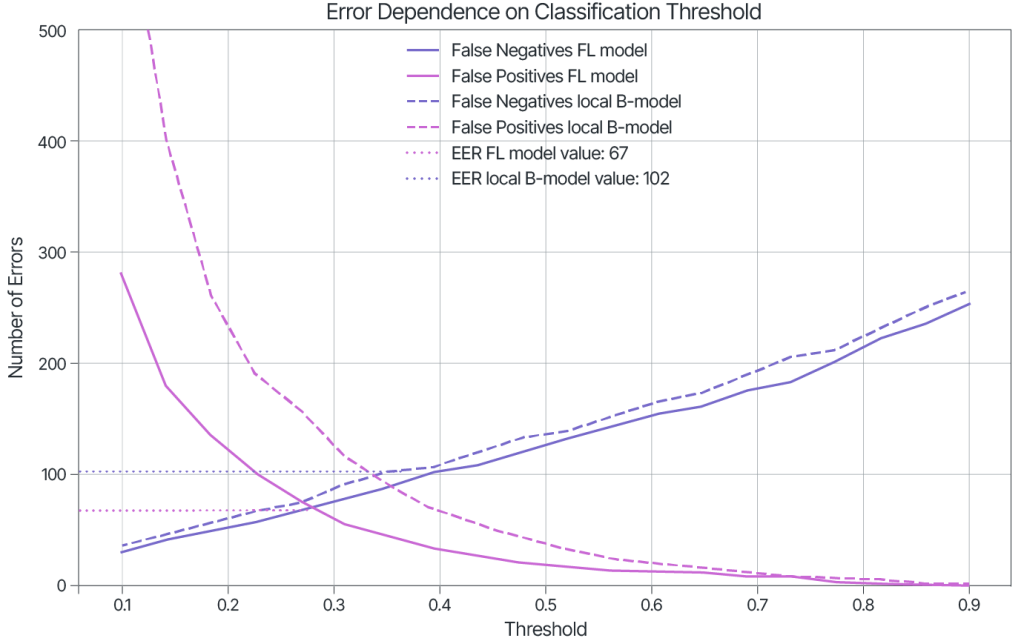
The output of the model is the probability that a transaction belongs to a fraud class. This allows the decision boundary to be set depending on which type of risk is preferred.
The figure shows the correlation between false positives and false negatives on the test set at different thresholds.
Equal Error Rate (EER) values, as a measure of model performance, can also be seen in the figure.
| EER of the local model | 102 |
| EER of FL model | 67 |
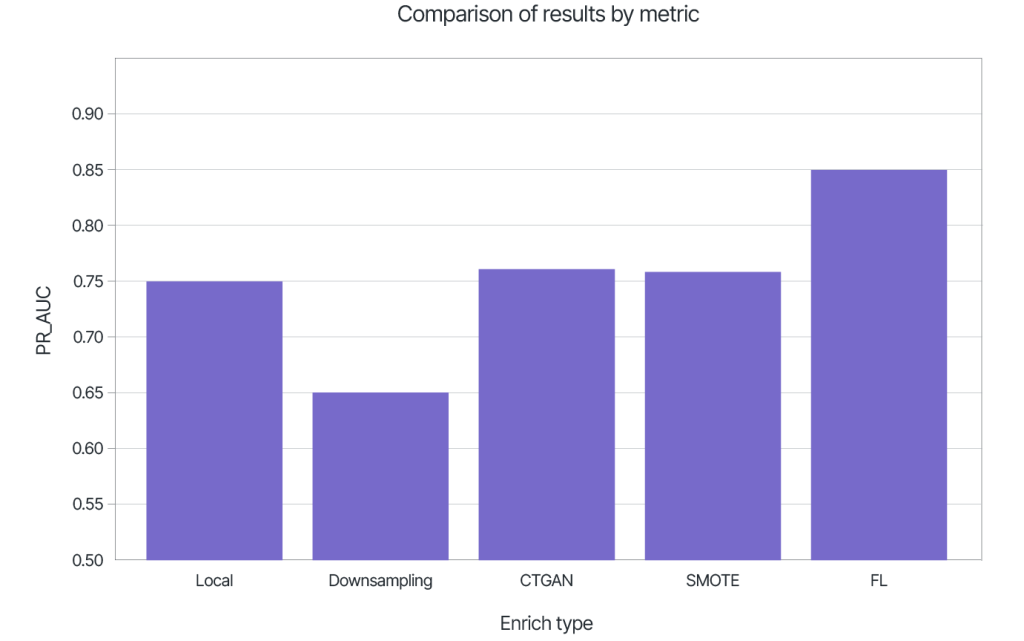
For the Random Forest model, using FL improves the PR-AUC quality metric to 0.848 (relative to 0.738 for data_A, 0.750 for data_B).
Let us analyze typical ways of solving the problem of data scarcity of a particular class, using data_B as an example set with a higher fraud rate.
Customers of smaller organizations deserve identical fraud protection, too.
FL allows such organizations to band together, leverage payment system data and, as a result, build models comparable in quality to the largest players.
For payment systems, the use of FL allows them to significantly reduce fraud losses, increase trust in the payment system itself, reduce risk, and monetize the knowledge extracted from their data through collaborative machine learning with small and medium-sized businesses.
Model improvement on the PR-AUC metric was about 10 points compared to local training.
Reduction of false positives by more than 50% at a threshold of 0.5.
As a result of the joint training, each participant received an identical version of the model, is now able to conduct independent inference, and, if necessary, rounds of refresher training at specified intervals, or as new data are accumulated.
Preserving privacy while increasing fraud detection efficiency.
Savings by participating in a mutually beneficial secure scheme.
Accelerating model updates by responding quickly to new types of fraud.

Additional resources