Confidential Сomputing for Machine Learning in the Oil and Gas industry

A group of companies consisting of more than 20 enterprises in the field of diagnosing flow and integrity throughout the oil and gas well system, from the wellbore to the reservoir, empowering their customers to make better decisions and improve asset performance.
The Customer invests a significant portion of annual revenues into R&D, collaborating with universities and industry partners to advance diagnostics. Their in-house expertise spans program design, data acquisition, tool and sensor manufacturing, software development, and data interpretation, establishing the Customer as a unique and trusted leader in through-barrier diagnostics.
All oil workers are very protective of their data. Access to data is strictly guarded, and this occurs not only between competing companies but also between subsidiaries and even within the same company, between different departments developing various fields. Maintaining the confidentiality of such data is the number one priority. In some cases, the situation is exacerbated by the fact that data cannot leave the borders of certain countries by law.
On the other hand, companies are actively developing predictive diagnostics for well operations using artificial intelligence methods. A clear obstacle to the development of ML algorithms is the unwillingness or inability of data owners to share their data with ML developers due to potential threats such as leaks, theft, and illegal use.
During the extraction and storage of gas, gas condensate, and oil, operators around the world face the problem of sand production from wells.
Sand production leads to equipment failure, reduced well productivity, and increased operational costs.
This problem is acute in the oil and gas industry, both at production wells and underground oil and gas storage facilities.
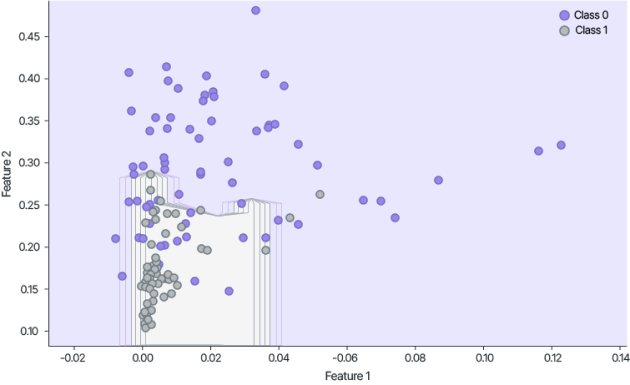
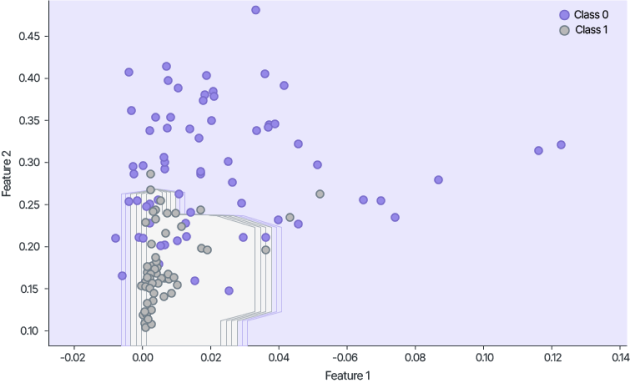
Thus, to comply with confidentiality requirements and train the models, relevant data owned by different entities was exchanged in encrypted form.
It is important to emphasize that the data was protected throughout the entire process, including the stages of machine learning and inference.

Guardora achieved full training of the ML model on encrypted data followed by inference on encrypted samples
In addition, if the model is decrypted, it will be applicable for inference on public data with the same characteristics. This is useful when the model is trained in the cloud or on third-party encrypted data and then used on its computational resources or its unclassified data
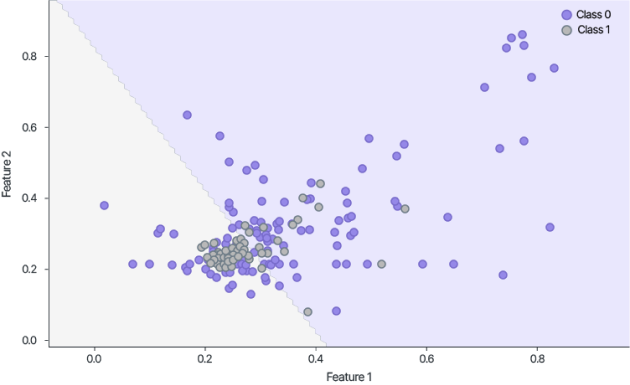
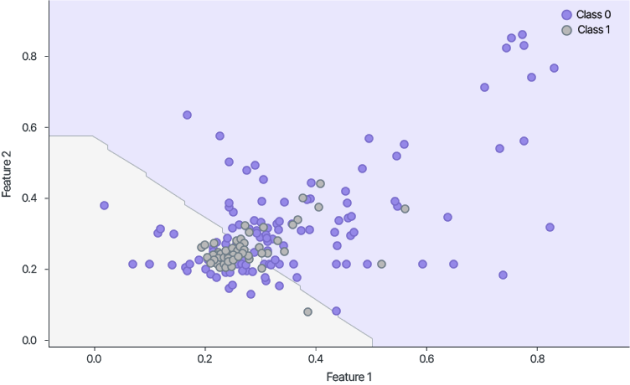
Guardora also trained the model on public data and then adapted it for the inference of encrypted samples
This was useful for a training sample that did not contain sensitive information, but the data that were processed subsequently were sensitive