

Training neural network models requires huge amounts of constantly updated data. Collecting, storing, processing, and transmitting such amounts results in enormous computation costs. Training models solely on new data leads to significant performance degradation (there is a "forgetting problem", when the model forgets previous examples after training on new data); on the other hand, storing all historical data is highly burdensome, if not impracticable. There is an objective need to reduce the volume of processed data while maintaining the same amount of knowledge (useful information in machine learning), so that models trained on these subsets can achieve as good performance as the original ones.
Many data reduction methods are based on selecting the most representative/valuable samples from the original datasets. This technique is rather straightforward and may seem effective, but when the number of selected data sets is significantly reduced, training on them may result in subpar model performance.
In contrast to these methods, Dataset Distillation, also called Dataset Condensation, is not a direct selection from existing data, but the synthesis of a small number of new objects S (synthetic data) that aggregate knowledge stored in the original data T and allow machine learning algorithms to be trained almost as efficiently as on original dataset (Figure 1).
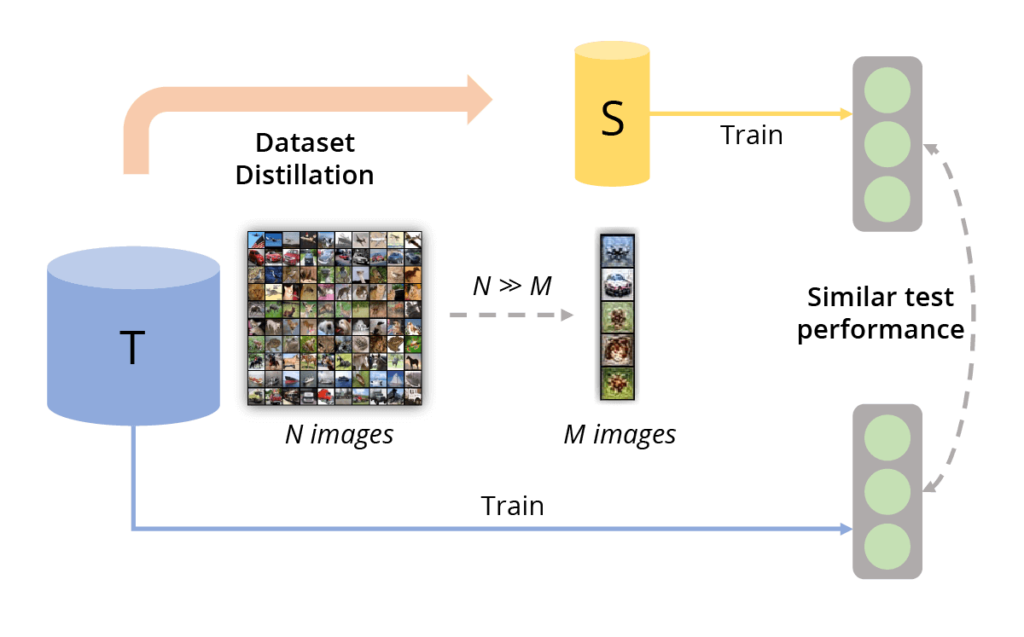
Fig. 1 (image source: [1]) An overview for dataset distillation. Dataset distillation aims to generate a small informative dataset such that the models trained on these samples have similar test performance to those trained on the original dataset.
This approach was first proposed in 2018 in [2]. The authors successfully reduced the MNIST dataset of 60,000 images of handwritten digits to just 10 elements (one representative image for each class)! The model achieved 94% training accuracy using synthetic data, which is comparable to 99% accuracy on the full dataset. Fig. 2 shows the main result from [2] and the synthetic data obtained in the MNIST and CIFAR10 tasks.

Fig. 2 (image source: [2]) The knowledge of tens of thousands of images is distilled into a few synthetic training images called distilled images. On MNIST, 10 distilled images can train a standard LENET with a fixed initialization to 94% test accuracy, compared to 99% when fully trained. On CIFAR10, 100 distilled images can train a network with a fixed initialization to 54% test accuracy, compared to 80% when fully trained.
Distillation methods classification
The idea of data distillation immediately attracted researchers’ attention, and soon new distillation methods were proposed (Fig. 3), including simultaneous distillation of both images and their labels ([3]). Originating as a method for optimizing image data, distillation was now applied to texts ([3], [4]), graphs ([5], [6]) and even recommender systems ([7]).
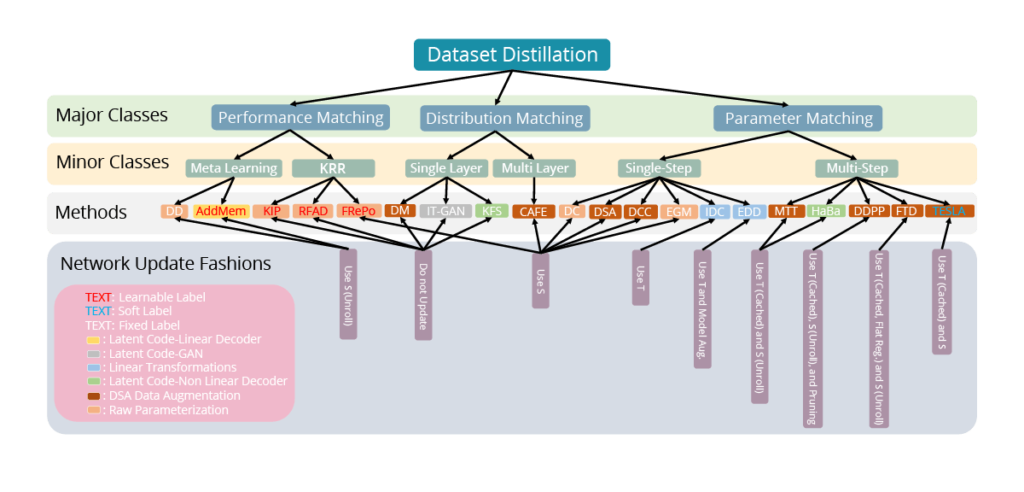
Fig. 3 (image source: [1]) Taxonomy of existing DD methods. A DD method can be analyzed from 4 aspects: optimization objective, fashion of updating networks, synthetic data parameterization, and fashion of learning labels.
Yet in the wide range of various methods, three mainstream approaches to distilled data effectiveness are clearly distinguished: Performance Matching, Parameter Matching, and Distribution Matching.
Performance matching
Performance matching aims to optimize a synthetic dataset such that neural networks trained on it could have the lowest loss on the original dataset. The goal is to achieve comparable performance and results on both synthetic and original data.
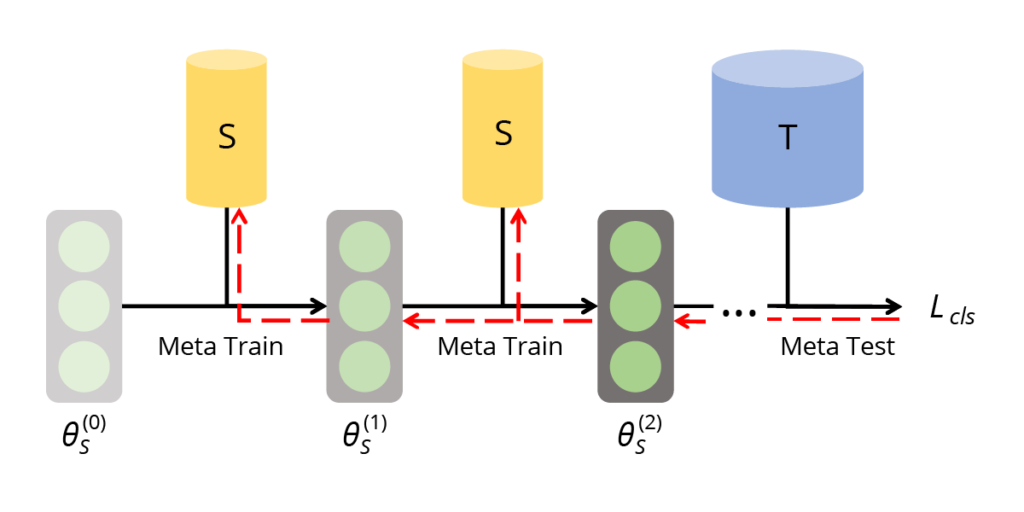
Fig. 4 (image source: [1]) Meta learning based performance matching. The bi-level learning framework aims to optimize the meta test loss on the real dataset T, for the model meta-trained on the synthetic dataset S.
Parameter matching
Parameter matching, on the other hand, aims to simultaneously train the neural network on both the synthetic dataset and the original dataset. This approach aims at encouraging the consistency of trained neural parameters in both cases. It can be further divided into two streams: single-step (gradient matching) and multistep (training trajectory matching).
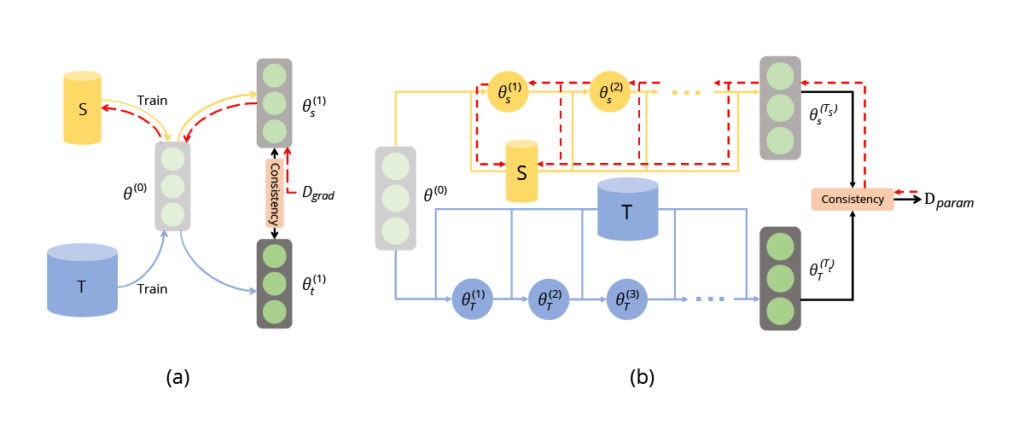
Fig. 5 (image source: [1]) (a) Single-step parameter matching. (b) Multi-step parameter matching. They optimize the consistency of trained model parameters using real data and synthetic data. For single-step parameter matching, it is equivalent to matching gradients. For multi-step parameter matching, it is also known as matching training trajectories.
Distribution matching
Unlike the previous two approaches, which aim to optimize the model, distribution matching directly optimizes the distance between data distributions. The goal here is to produce synthetic data that is as close as possible to the distribution of real data.
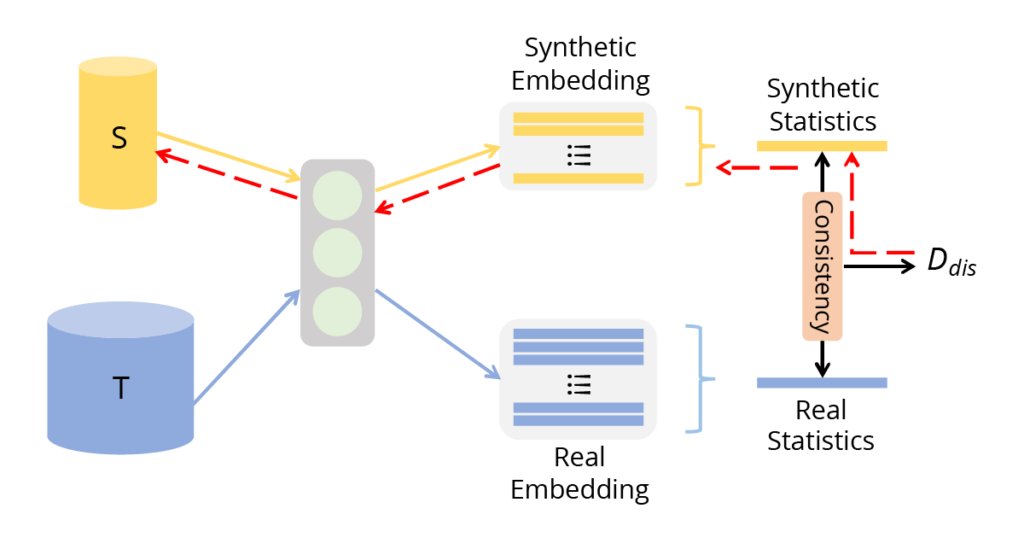
Fig. 6 (image source: [1]) Distribution matching. It matches statistics of features in some networks for synthetic and real datasets.
Data distillation as a privacy protection method for original data
It is important to note that none of the approaches described above require visual similarity between the distilled and original images. The results of many distillation methods are more similar to noise than to the original images (Fig. 2). Due to this property, data distillation has been used not only for dataset compression but also for visual anonymization of data.
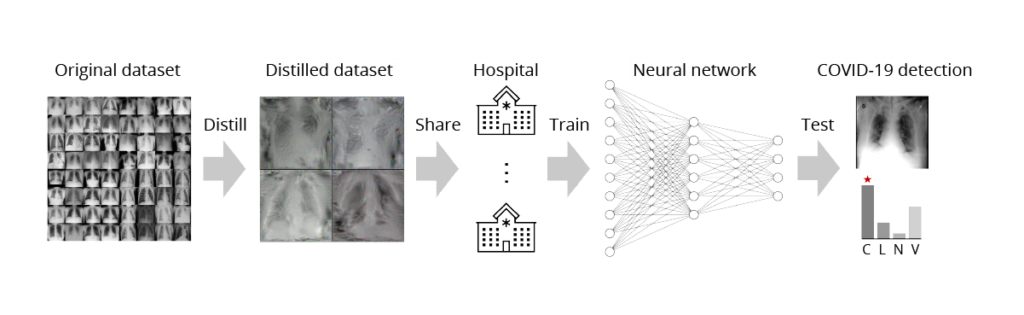
One practical example is potentially secure transmission of medical images between hospitals ([8], [9]). Medical data sharing is known to be challenging due to data privacy protection and the enormous cost of transferring and storing a large number of high-resolution medical images. However, this challenge can be overcome by transmitting distilled data instead of the original data (Fig. 7).
Distillation can also be used in federated learning ([10]). In the traditional approach, clients train locally and send large model weights to the server during each iteration instead of sharing sensitive data. However, an alternative approach assumes that clients can distill their data and send the synthesized data to the server where a global model will be trained on it. This approach effectively minimizes the frequency of costly communications and ensures the confidentiality of the original data.
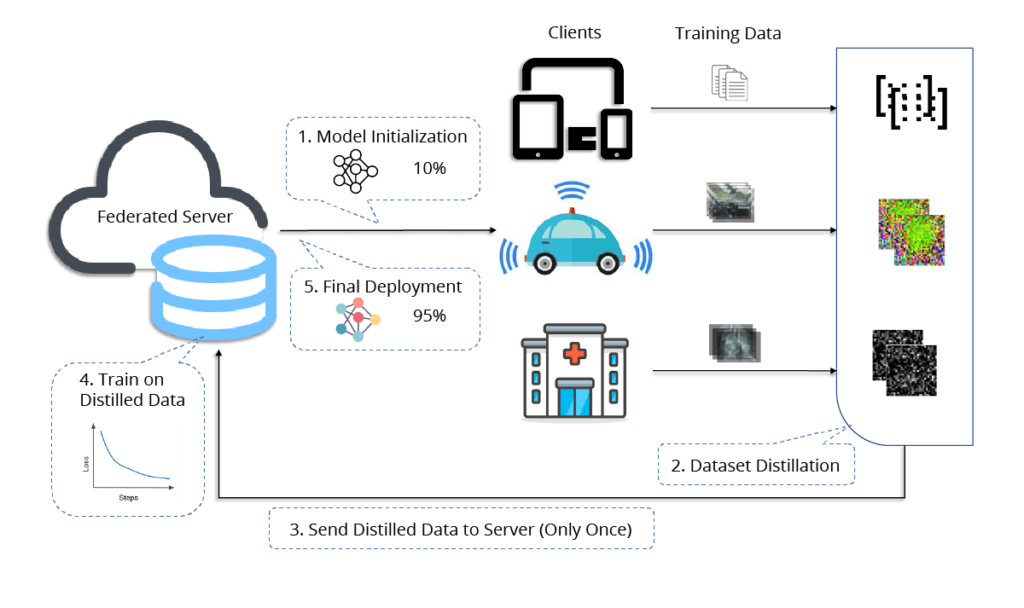
Fig. 8 (image source: [10]) Distilled One-Shot Federated Learning. (1) The server initializes a model which is broadcast to all clients. (2) Each client distills their private dataset and (3) transmits synthetic data, labels and learning rates to the server. (4) The server fits its model on the distilled data and (5) distributes the final model to all clients.
But is it really safe to use distilled data instead of original data? In [11], the authors provide empirical evidence of the effectiveness of data protection through distillation. They perform a series of attacks on models trained on distilled data to determine the probability that a certain input belongs to the original dataset (so-called Membership Inference Attacks, MIA). Their results show that MIA have a success probability of about 50%, which is comparable to random guessing and indicates a good defense.
But these claims are disputed by the authors of [12]. They argue that theoretical analysis and empirical evaluations in [11] do not provide statistically significant evidence that data distillation does improve the privacy of original data.
Differential Privacy
Nevertheless, the idea of using data distillation to preserve the privacy of original data sparked an interest in many researchers, and results with rigorous proofs have been obtained in this field. Thus in [13] DP-SGD is applied during distillation for the first time. DP-SGD (Differentially Private Stochastic Gradient Descent) is a widely used differential privacy algorithm that involves introducing calibrated Gaussian noise into the gradients during training. The fundamental principle of differential privacy is to protect the privacy of each individual element of the dataset, providing among other things resilience to potential attacks such as in [11].
The authors of [14] try to propose a more efficient method of differentially private distillation, but face another problem ― high computational complexity (it requires parallel utilization of hundreds of V100 GPUs ― resources that are inaccessible to many). Solving this problem, they propose an alternative with a computational cost manageable by a single V100 GPU. If we evaluate the efficiency of the data synthesized by their method, then for the MNIST dataset and 10 distilled images (1 for each class) we get an accuracy of 94.7% (almost at the 2018 level, but with privacy guarantees), while the same method without DP-SGD (and thus without privacy guarantees) reaches 98.2%.
Therefore, despite the availability of differentially private distillation methods, it is still too early to talk about their widespread application in practice, as they make the already rather complicated distillation process even more arduous and resource-intensive, and reduce the efficiency of the obtained synthetic data.
Other disadvantages of distillation, such as the lack of flexibility and versatility of synthetic data, should also not be overlooked: distilled data are tailored, firstly, for a specific classification task (with specific labels); secondly, for a specific model, so it is unlikely to be possible to train a neural network of arbitrary architecture on distilled data to the desired quality. Distilled data is still not a full-fledged substitute for the original data.
All this makes data distillation undoubtedly interesting, but rather difficult for practical use to ensure real data privacy. However, distillation methods are rapidly evolving and improving!
Sources
[1] Ruonan Yu, Songhua Liu and Xinchao Wang. Dataset distillation: A comprehensive review. arXiv preprint arXiv:2301.07014, 2023
[2] Tongzhou Wang, Jun-Yan Zhu, Antonio Torralba and Alexei A Efros. Dataset distillation. arXiv preprint arXiv:1811.10959, 2018
[3] Ilia Sucholutsky and Matthias Schonlau. Soft-label dataset distillation and text dataset distillation. In 2021 International Joint Conference on Neural Networks (IJCNN), pp. 1–8. IEEE, 2021
[4] Yongqi Li and Wenjie Li. Data distillation for text classification, arXiv preprint arXiv:2104.08448, 2021
[5] Wei Jin, Lingxiao Zhao, Shichang Zhang, Yozen Liu, Jiliang Tang and Neil Shah. Graph condensation for graph neural networks, arXiv preprint arXiv:2110.07580, 2021
[6] Jin, Wei and Tang, Xianfeng and Jiang, Haoming and Li, Zheng and Zhang, Danqing and Tang, Jiliang and Yin, Bing. Condensing graphs via one-step gradient matching, in Proceedings of the 28th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, 2022, pp. 720–730
[7] Noveen Sachdeva, Mehak Preet Dhaliwal, Carole-Jean Wu and Julian McAuley. Infinite recommendation networks: A data-centric approach, arXiv preprint arXiv:2206.02626, 2022
[8] Li, Guang and Togo, Ren and Ogawa, Takahiro and Haseyama, Miki. Dataset distillation for medical dataset sharing, arXiv preprint arXiv:2209.14603, 2022
[9] Li, Guang and Togo, Ren and Ogawa, Takahiro and Haseyama, Miki. Compressed gastric image generation based on soft-label dataset distillation for medical data sharing, Computer Methods and Programs in Biomedicine, vol. 227, p. 107189, 2022
[10] Yanlin Zhou, George Pu, Xiyao Ma, Xiaolin Li and Dapeng Wu. Distilled one-shot federated learning, arXiv preprint arXiv:2009.07999, 2020
[11] Tian Dong, Bo Zhao and Lingjuan Lyu. Privacy for free: How does dataset condensation help privacy? arXiv preprint arXiv:2206.00240, 2022
[12] Nicholas Carlini, Vitaly Feldman and Milad Nasr. No Free Lunch in "Privacy for Free: How does Dataset Condensation Help Privacy", arXiv preprint arXiv:2209.14987, 2022
[13] Dingfan Chen, Raouf Kerkouche and Mario Fritz. Private set generation with discriminative information, arXiv preprint arXiv:2211.04446, 2022
[14] Margarita Vinaroz and Mi Jung Park. Differentially Private Kernel Inducing Points using features from ScatterNets (DP-KIP-ScatterNet) for Privacy Preserving Data Distillation, arXiv preprint arXiv:2301.13389, 2024


